| [CVPR2022 | 您所在的位置:网站首页 › 检索 论文 › [CVPR2022 |
[CVPR2022
|
个人阅读见解,欢迎大家交流讨论指正~ 一、研究背景视觉外观被认为是跨模态检索中理解图像的最重要线索,而有时图像中出现的场景文本(Scene text)可以为理解视觉语义提供有价值的信息。现有的跨模态检索方法大多忽略了场景文本信息的使用,并且若直接添加这些信息可能会导致无场景文本场景中的性能下降。 作为最重要的多模态理解任务之一,跨模态检索因其在新闻搜索和产品检索等领域的重要应用而备受关注。跨模态text-to-image检索旨在根据查询的文本内容与图像视觉外观之间的相关性,返回最相关的候选对象。 跨模态检索:旨在返回给定文本或图像查询的相关图像或文本描述。 大多数方法学习联合跨模态嵌入空间(joint cross-modal embedding space)为语义相关的image-text对生成更相近的表示。自深度学习时代以来,跨模态检索的视觉表示一直在改进,从grid-based CNN改进为预训练的对象检测器。与此同时,人们开发了更精细的image-text对齐方法,例如注意机制、迭代匹配以及基于图形的图像特征和文本嵌入之间的关系推理。这些方法大多依赖从Visual Genome (VG)数据集上预训练的Faster-RCNN检测器中提取的RoI(感兴趣区域)特征,这限制了在域外视觉概念(out-of-domain vision concepts)上的性能。(这个“域外视觉概念”我不李姐T_T’,如果“域”代表RoI的话那应该用out-of-region呀,那我感觉就不能理解为RoI了) 相比之下,ViSTA直接将image patches作为输入,并基于最新的对比图像文本预训练范式,该范式能够以更快的推理速度通过端到端训练获得更好的性能。 视觉语言预训练:已经成为多模态理解的主流范式,它可以显著提高各种视觉和语言任务的性能,例如跨模态检索和视觉问答(VQA)等。这些方法大多采用基于transformer体系结构,可分为single-encoder and dual-encoder pre-training。 single-encoder将图像和文本与多模态transformer进行融合,以进行交互,在各种下游任务中表现出了高准确度。为了加快推理阶段并适应更多的视觉类别,使用基于网格的图像特征和新提出的patch-based的图像嵌入方法进行端到端训练,直接将图像像素或patch和text embedding作为输入。然而,对于大规模的跨模态检索任务来说,这些方法的计算代价仍然巨大且不切实际。相反,dual-encoder分别对图像和文本进行编码,从而可以以线性时间复杂度计算image-text对的相似性。尽管百万尺度image-text对比预训练大大提高了跨模态检索任务的性能,但是学习特定的细粒度视觉概念,例如,从图像中学习场景文本语义,仍然是困难且无效的。相比之下,ViSTA将视觉和场景文本整合到基于full transformer的dual-encoder体系结构中,将图像patch、场景文本和查询文本作为联合跨模态检索的输入。 Scene text in vision and language:作为text-based图像字幕和Text-VQA等应用的扩展。所有方法都利用OCR(光学字符识别)形成scene text embedding,遵循RoI区域特征的single-stream的典型架构。场景文本检索任务的其他工作旨在返回包含查询词的图像,基于CNN的融合方法集成了场景文本和视觉外观,以提高特定场景中细粒度图像分类的性能。最近,StacMR引入了场景文本感知(scene text aware)跨模态检索,将场景文本视为一种附加模式,利用GCN(图卷积网络)获得图像和场景文本的上下文表示,以进行最终融合。 与所有这些方法不同的是,ViSTA利用full transformer blocks对图像patch和场景文本进行mid-level融合编码,可以适应场景文本感知和无场景文本场景。 注:场景文本感知(scene text aware)可以理解为图片中存在场景文本的情况 三、ViSTAViSTA是一个用视觉和场景文本聚合进行跨模态检索的full transformer架构。具体来说,ViSTA利用transformer block直接对图像块进行编码,并融合场景文本嵌入,学习用于跨模态检索的聚合视觉表示。 为了解决场景文本的模态缺失问题,提出了一种基于融合标记(fusion token)的transformer聚合方法,只通过融合标记交换必要的场景文本信息,并专注于每个模态中最重要的特征。 为了进一步增强视觉模态,开发了双重对比学习损失(dual contrastive learning losses),将image-text对和融合文本对嵌入到一个共同的跨模态空间中。 与现有方法相比,ViSTA能够将相关的场景文本语义与视觉外观聚合在一起,从而在无场景文本和场景文本感知(scene text aware)的情况下改进结果。 ViSTA分别用多头注意力Transformer encoder提取特征(Vision encoder, Scene text encoder, Text transformer)。 Transformer encoder由若干个连续的Transformer组成,每个Transformer由Multi-headed Self-Attention (MHSA), Layer Normalization (LN), and Multilayer Perceptron (MLP) blocks组成。Transformer 原理和公式不做赘述。 Scene Text 由谷歌OCR API进行识别得到结果 O = { o j word , o j bbox } j = 1 N o \mathcal{O}=\left\{\mathbf{o}_{j}^{\text {word }}, \mathbf{o}_{j}^{\text {bbox }}\right\}_{j=1}^{N_{o}} O={ojword ,ojbbox }j=1No,结果由文字识别结果及文字位置框构成; OCR结果与模态类型 S t y p e S^{type} Stype和位置嵌入 S t o k e n _ i d S^{token\_id} Stoken_id组合为: S init = Embedding ( o word ) + S type + S token_id \mathbf{S}_{\text {init }}=\operatorname{Embedding}\left(\mathbf{o}^{\text {word }}\right)+\mathbf{S}^{\text {type }}+\mathbf{S}^{\text {token\_id }} Sinit =Embedding(oword )+Stype +Stoken_id 按照Text-VQA中的方法,由BERT编码的场景文本嵌入可以使用规范化的边界框坐标 o bbox \mathbf{o}^{\text {bbox }} obbox 与OCR tokens的4维位置信息进一步结合,并可以表示为: S 0 = B E R T ( S init ) + F linear ( o bbox ) \mathbf{S}_{0}=\mathbf{B E R T}\left(\mathbf{S}_{\text {init }}\right)+\mathbf{F}_{\text {linear }}\left(\mathbf{o}^{\text {bbox }}\right) S0=BERT(Sinit )+Flinear (obbox ) 3.2视觉和场景文本聚合为了处理场景文本感知和无场景文本的跨模态检索任务,作者使用不同的标记(图像标记或融合标记)来区分不同的场景,标记根据OCR是否有识别结果作为判断依据。 在无场景文本场景中,视觉塔(vision tower)退化为纯视觉编码器模型,并输出[IMG]标记的图像特征作为最终特征。在场景文本感知场景中,使用场景文本编码器来学习场景文本的语义特征。视觉塔简单地添加了视觉的 L f L_f Lf层( f f f在论文中未指定)和场景文本聚合层,以在图像模态中进行中级融合,并从额外的融合标记[FUS]输出融合特征作为最终特征。
如图3的详细结构所示,视觉场景文本聚合层由来自两个编码器组成。为了交换视觉和场景文本的相关信息,这两层添加了一个新的共享特殊融合标记[FUS]。用 V l V_l Vl和 S l S_l Sl表示聚合阶段中第 l l l个视觉编码器和场景文本编码器的输入图像标记和场景文本标记。第 l l l个视觉和场景文本聚合的输入融合标记用 F l F_l Fl表示。 聚合阶段中的视觉transformer层的工作流公式更新为: Y l ← MHSA ( L N ( [ V l ; F l ] ) ) + [ V l ; F l ] [ V l + 1 ; V F U S ] ← MLP ( L N ( Y l ) ) + Y l , 其 中 V F U S 是 与 融 合 标 记 相 对 应 的 输 出 图 像 特 征 。 \begin{aligned} &\mathbf{Y}_{l} \leftarrow \operatorname{MHSA}\left(\mathrm{LN}\left(\left[\mathbf{V}_{l} ; \mathbf{F}_{l}\right]\right)\right)+\left[\mathbf{V}_{l} ; \mathbf{F}_{l}\right] \\ &{\left[\mathbf{V}_{l+1} ; \mathbf{V}_{\mathrm{FUS}}\right] \leftarrow \operatorname{MLP}\left(\mathrm{LN}\left(\mathbf{Y}_{l}\right)\right)+\mathbf{Y}_{l}} \end{aligned} ,其中\mathbf{V}_{\mathrm{FUS}}是与融合标记相对应的输出图像特征。 Yl←MHSA(LN([Vl;Fl]))+[Vl;Fl][Vl+1;VFUS]←MLP(LN(Yl))+Yl,其中VFUS是与融合标记相对应的输出图像特征。 同样的,场景文本transformer层的工作流公式更新为: Y l ← MHSA ( LN ( [ S l ; F l ] ) ) + [ S l ; F l ] [ S l + 1 ; S F U S ] ← MLP ( LN ( Y l ) ) + Y l \begin{aligned} &\mathbf{Y}_{l} \leftarrow \operatorname{MHSA}\left(\operatorname{LN}\left(\left[\mathbf{S}_{l} ; \mathbf{F}_{l}\right]\right)\right)+\left[\mathbf{S}_{l} ; \mathbf{F}_{l}\right] \\ &{\left[\mathbf{S}_{l+1} ; \mathbf{S}_{\mathrm{FUS}}\right] \leftarrow \operatorname{MLP}\left(\operatorname{LN}\left(\mathbf{Y}_{l}\right)\right)+\mathbf{Y}_{l}} \end{aligned} Yl←MHSA(LN([Sl;Fl]))+[Sl;Fl][Sl+1;SFUS]←MLP(LN(Yl))+Yl 最后将 V F U S V_{FUS} VFUS和 S F U S S_{FUS} SFUS元素求和 F l + 1 F_{l+1} Fl+1后embedding(下面的 F i n i t F^{init} Finit应该就是 F l + 1 F_{l+1} Fl+1): F 0 = F init + F type + F token_id , F 0 是 视 觉 和 场 景 文 本 聚 合 层 的 第 一 个 输 入 融 合 特 征 。 \mathbf{F}_{0}=\mathbf{F}^{\text {init }}+\mathbf{F}^{\text {type }}+\mathbf{F}^{\text {token\_id }},F_0是视觉和场景文本聚合层的第一个输入融合特征。 F0=Finit +Ftype +Ftoken_id ,F0是视觉和场景文本聚合层的第一个输入融合特征。 特殊的融合标记[FUS]在两个编码器中共享,扮演着两个编码器之间的桥梁角色。 按照论文的表述,融合标记应该是只选取transformer其中一层进行计算。 3.3跨模态对比学习总损失: L total = α L i t c + ( 1 − α ) L f t c \mathcal{L}_{\text {total }}=\alpha \mathcal{L}_{i t c}+(1-\alpha) \mathcal{L}_{f t c} Ltotal =αLitc+(1−α)Lftc,其中, L i t c \mathcal{L}_{i t c} Litc是图像-文本对比损失, L f t c \mathcal{L}_{f t c} Lftc是融合-文本对比损失;如果提取的OCR结果为无,则 L f t c \mathcal{L}_{f t c} Lftc不会添加到总损失中; 将N个图像和文本对作为一个batch,融合-文本对比损失的目的是最大化N个正确匹配对之间的相似性,最小化 N 2 − N N^2-N N2−N个错误匹配对之间的相似性: L f t c = 1 2 ( L f 2 t + L t 2 f ) \mathcal{L}_{f t c}=\frac{1}{2}\left(\mathcal{L}_{f 2 t}+\mathcal{L}_{t 2 f}\right) Lftc=21(Lf2t+Lt2f); 融合文本对比学习的目标是最小化融合标记和文本[CLS]之间的对比损失: L f 2 t = − 1 N ∑ i = 1 N log exp ( f i ⊤ t i / σ ) ∑ j = 1 N exp ( f i ⊤ t j / σ ) L t 2 f = − 1 N ∑ i = 1 N log exp ( t i ⊤ f i / σ ) ∑ j = 1 N exp ( t i ⊤ f j / σ ) \begin{aligned} \mathcal{L}_{f 2 t} &=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp \left(f_{i}^{\top} t_{i} / \sigma\right)}{\sum_{j=1}^{N} \exp \left(f_{i}^{\top} t_{j} / \sigma\right)} \\ \mathcal{L}_{t 2 f} &=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp \left(t_{i}^{\top} f_{i} / \sigma\right)}{\sum_{j=1}^{N} \exp \left(t_{i}^{\top} f_{j} / \sigma\right)} \end{aligned} Lf2tLt2f=−N1i=1∑Nlog∑j=1Nexp(fi⊤tj/σ)exp(fi⊤ti/σ)=−N1i=1∑Nlog∑j=1Nexp(ti⊤fj/σ)exp(ti⊤fi/σ) 图像-文本对比损失和融合-文本对比损失公式类似,只是将 f i f_i fi换成了 v i v_i vi。 四、实验 4.1实验设置不同任务的所有预训练、微调和测试设置如下: 评估指标:实验都是根据最高return中包含匹配对的百分比进行评估的,即:R@1, R@5和R@10 当场景文本的模态丢失时,ViSTA在这些数据集中不受影响,并且由于基于融合标记的视觉和场景文本聚合,在下游任务中仍然表现良好。
作者提出了一种有效的视觉和场景文本聚合transformer,用于跨模态学习场景文本增强的视觉表示,将传统和场景文本感知的跨模态检索任务统一在一个框架中。为了处理没有场景文本的图像,作者提出了一种基于融合标记的聚合方法(只通过融合标记共享相关信息),以及一种双重对比学习方法来增强视觉特征。实验结果表明,ViSTA在场景文本感知检索和无场景文本检索方法上都具有良好的性能,证明了该框架的有效性。 当场景文本作为一种附加模态是必要的时,所提出的方法也可以应用于其他视觉和语言任务。场景文本聚合的作用和贡献还取决于包含相关场景文本语义的图像的百分比,以及特定任务中视觉外观和场景文本之间的相关性。 更广泛的影响——由于所提出的方法可以使用从网络上收集的大量图像和文本对进行训练,因此在生产过程中应进行进一步的数据分析、平衡和清理,以减轻分布偏差和错误标记数据造成的负面社会影响。 |


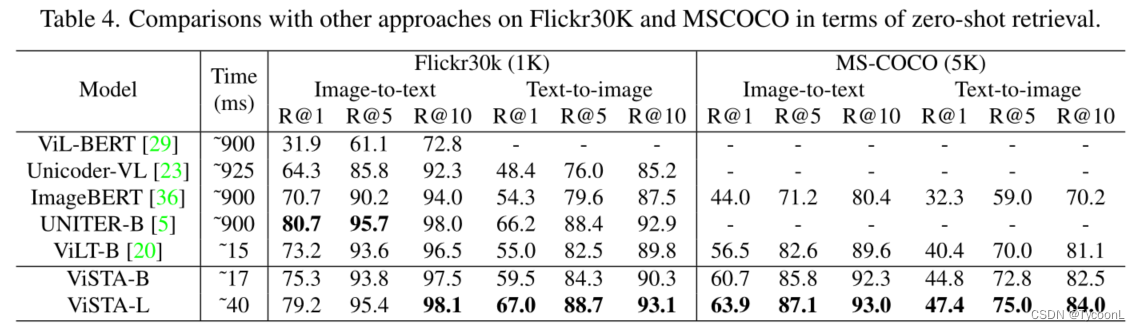
 数据集:场景文本感知跨模式检索任务在COCO文本字幕(CTC)数据集上进行评估,传统跨模式检索实验在Flickr30K和MSCOCO上进行,包括图像到文本和文本到图像检索任务
数据集:场景文本感知跨模式检索任务在COCO文本字幕(CTC)数据集上进行评估,传统跨模式检索实验在Flickr30K和MSCOCO上进行,包括图像到文本和文本到图像检索任务 ViSTA-S在场景文本感知图像文本检索任务R@1 CTC-1k 上的性能分别提高了8.4%和5.4%。与STARNet相比,STARNet使用GCN获得场景文本的表示以进行融合,作者使用BERT对其进行细化。视觉编码器上的自注意力学习图像中的长期依赖性,并帮助ViSTA模型学习patches之间的关系。视觉和场景文本聚合层学习视觉和场景文本模式的联合分布,并优化了表示空间。
ViSTA-S在场景文本感知图像文本检索任务R@1 CTC-1k 上的性能分别提高了8.4%和5.4%。与STARNet相比,STARNet使用GCN获得场景文本的表示以进行融合,作者使用BERT对其进行细化。视觉编码器上的自注意力学习图像中的长期依赖性,并帮助ViSTA模型学习patches之间的关系。视觉和场景文本聚合层学习视觉和场景文本模式的联合分布,并优化了表示空间。 
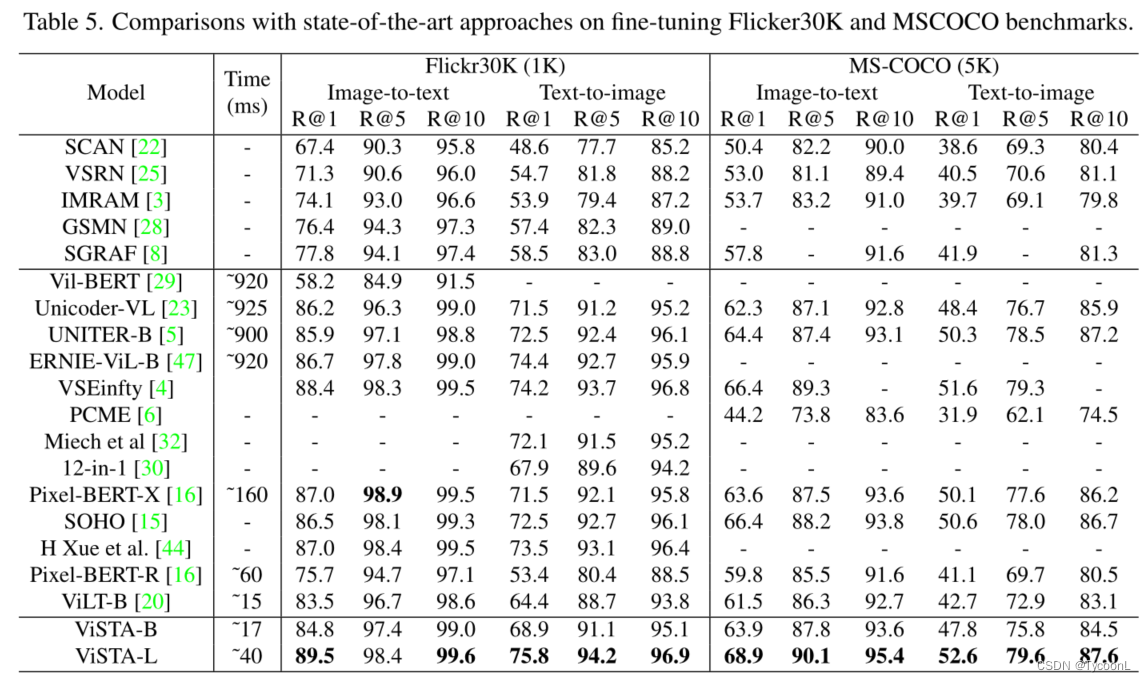

 定性比较:为了进行视觉比较,作者例举了两个例子。如图4所示,基于“网球”、“1970”和“1971”的查询,ViSTA模型匹配正确的图像,而没有场景文本嵌入的ViTSA检索到令人困惑的结果。在第二个例子中,“粘性热狗”被完美地捕捉。对于文本检索任务,如图5所示,从图像中提取的场景文本具有语义信息,并包含在使用ViSTA检索的结果中,而如果没有场景文本嵌入,则效果不佳。
定性比较:为了进行视觉比较,作者例举了两个例子。如图4所示,基于“网球”、“1970”和“1971”的查询,ViSTA模型匹配正确的图像,而没有场景文本嵌入的ViTSA检索到令人困惑的结果。在第二个例子中,“粘性热狗”被完美地捕捉。对于文本检索任务,如图5所示,从图像中提取的场景文本具有语义信息,并包含在使用ViSTA检索的结果中,而如果没有场景文本嵌入,则效果不佳。 
【本文地址】